# Music
&
# Big Data
-
October 2017 - Ecole Centrale de Nantes
*Guillaume Gardey*
## Planning
* Session 1
* Talk & QA: *Music & Web - Architecture & Technology Overview*
* Lab 1: Working with APIs
* Session 2
* Talk & QA: *Music & Big Data - Overview of challenges & technologies*
* Lab 2: Introduction to Data Processing - Python/Pandas
Note:
* General description and organization of the 3 sessions
## Big Data
> describes *large* amount of data (structured or unstructured) that
are difficult to process using traditional database and software
## Big Data
> Big data usually includes data sets with sizes beyond the ability of commonly used
software tools to capture, curate, manage, and process data within a tolerable elapsed time.
## Big Data

~
Note:
* 1 TB: ~2000h CD quality / 17,000 hours at 128kbs 2 years 24/7
* Library of congress ~10TB of printed data (26 millions books)
* 1 PB: 1PB of audio (mp3) would take 2000 years to play
* 1 EB: 1 gram of DNA can theoretically hold 455 exabytes
* 1 ZB: is equivalent to 152 million years of high-definition video
## Big Data - The 3 Vs... (and more)
### Volume
* large data sets
* information is not sampled
### Velocity
* rapidly changing
* available in real-time
### Variety
* different type: text, images, audio, video, ...
* structured: JSON, XML, ...
* (un|semi) structured: email, images, audio, music, text
### ... and more Vs
* **Veracity**
* how much trust can be put in the data
* **Value**
* eventually drives revenues or new features for companies
* **Variability**
* no fixed data or schema
* evolution in time
## Big Data in Music
-
## Where ?
### Content
* Audio
* Metadata
* Lyrics
### Events
* Listening patterns
* Application events
* User activity
* Social media data
### Derived data
* Crowd sourced data
* Recommendations
* Playlists
* User content
## Example: Big Data @ Spotify
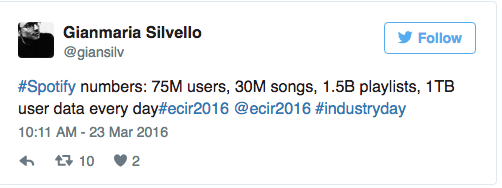
* 42PB Storage
* 200TB data generated / day
* 1300 Servers
Note:
* Figures in 2015, probably around 1600 servers now depending on literature
### Algorithms & Data Structures
* Algorithmic & Complexity
* Data Structures
### Complexity
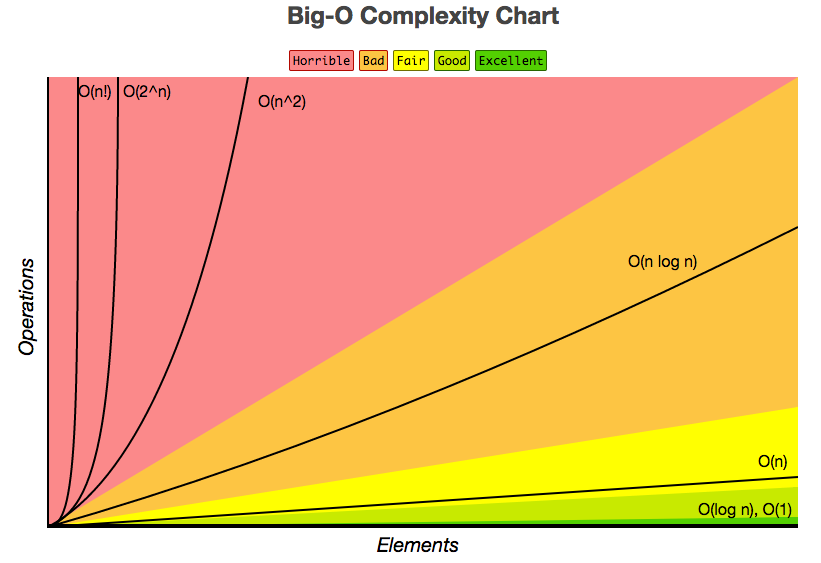
Note:
* 1 billion elements 10^9 / 1GHz 10^9
* O(n) linear: 1 billion operations / 1s
* O(n2) quadratic: 10^18 operations / 10^19 s = ~32 years
* O(log(n)) logarithmic: 20 operations / 0.01 microseconds
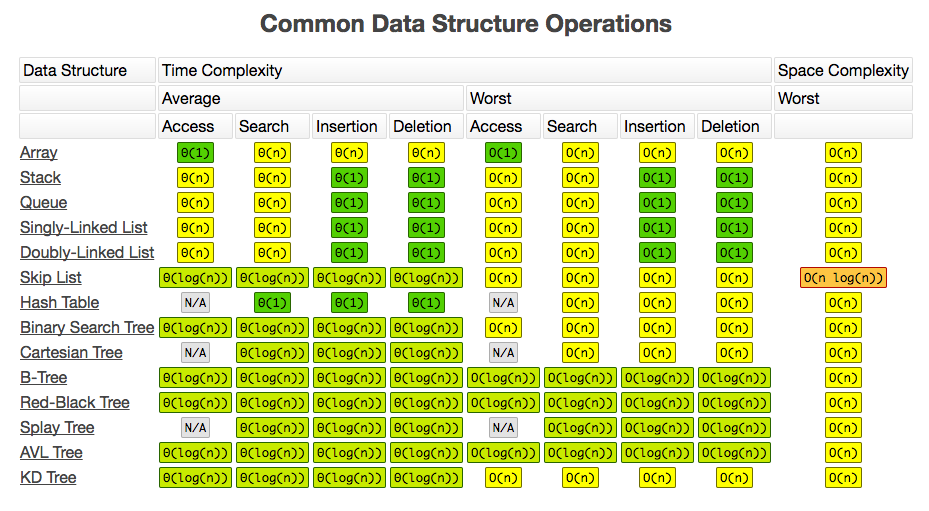
### Data structures
### Program optimization
* CPU
* Memory
* IO
* Network
### Parallelism
* Multi**threading**
* Multi**processing**
### Vertical Scaling
* Same server
* More
* CPU
* Memory
* Storage
### Vertical Scaling
Note:
* AWS: x1.32xlarge: 128cpu/1952GB RAM/2x1920GBSSD
* Dell: 96cpu/6TB RAM/24 disks (x8TB = 192TB)/
### New paradigms
* Dedicated hardware
* GPU (Graphical Process Unit)
* FPGA (Field Programmable Gate Array)
* New paradigm
* DNA Computing
* Quantum Computing
### Horizontal scaling
Distribute resources and work to many computers
### Horizontal Scaling
### Horizontal Scaling
* Distributed Systems
* Clusters
* Sharding
* Share Nothing
* Cloud
## Big Data & Hadoop
* Fundations
* Google File System (2003)
* Google MapReduce (2004)
* Google BigTable (2005/2006)
* Open Source implementation
* *Apache Nutch* (web crawler)
* Development moved to the *Hadoop* project in 2006
### Map-Reduce
> A programming model for processing and generating large data sets with a parallel,
distributed algorithm on a cluster
> Takes advantage of the locality of data, processing it near the place it is
stored in order to reduce the distance over which it must be transmitted.
Note:
* Distribution of work
* Data locality and compute
### Map-Reduce
Parallel computations on a cluster
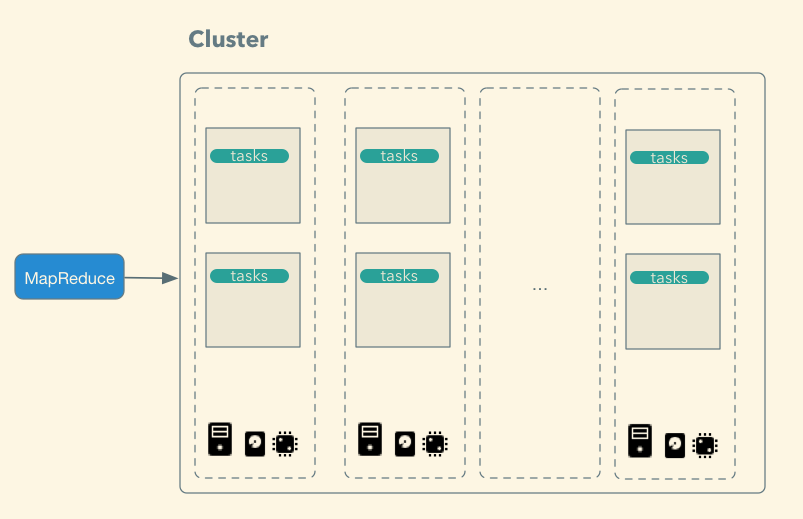
### Map-Reduce
Data locality
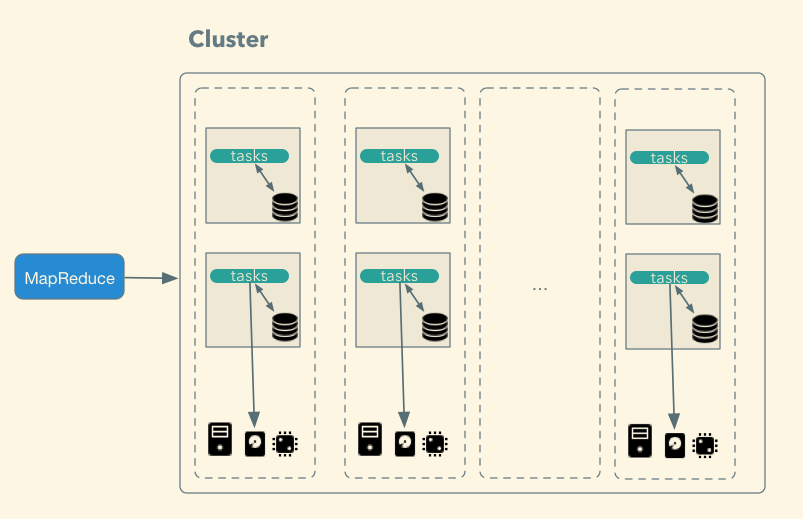
### Map-Reduce
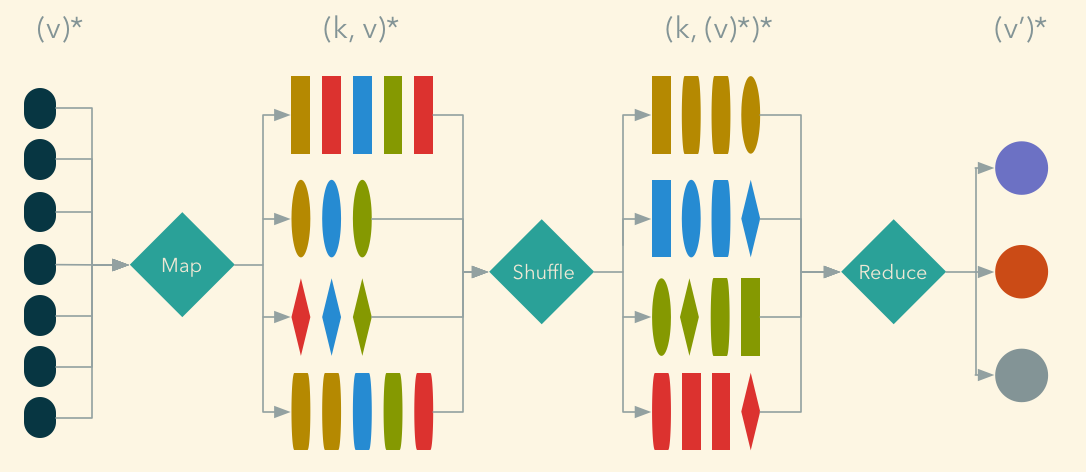
### Map-Reduce - Word Count
def map(document):
for word in document:
emit(word, 1)
def reduce(word, values):
count = 0
for value in values:
count += value
emit(word, count)
### Map-Reduce - Word Count
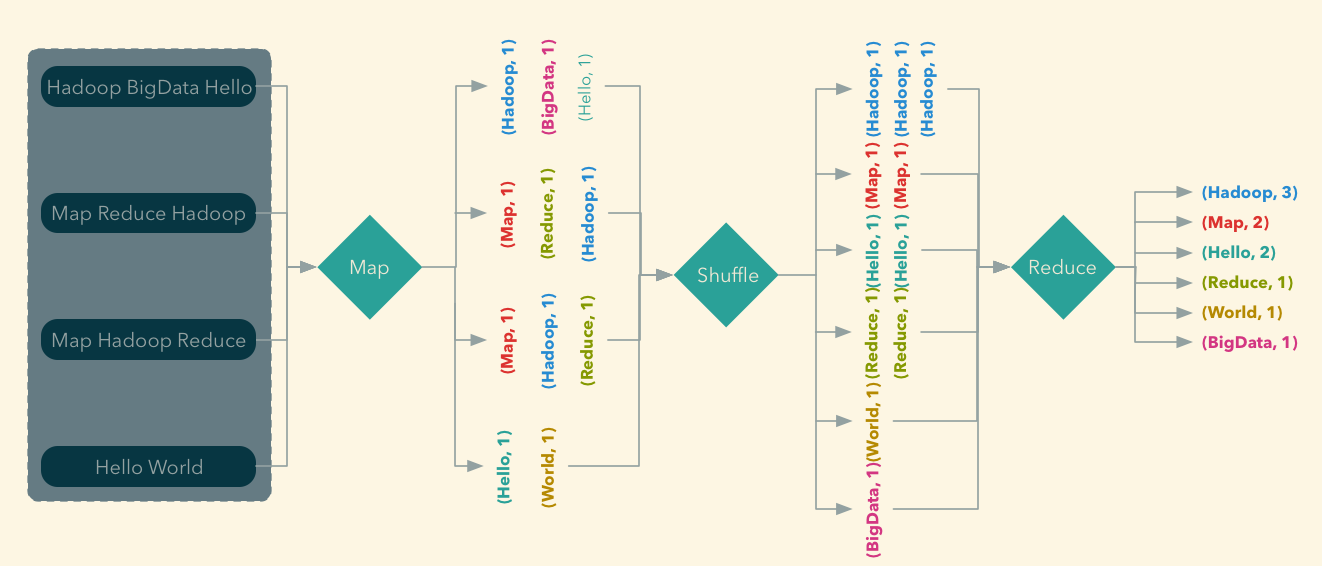
### Map-Reduce - What Now?
Relatively simple computational model
*but*
Many problems can be translated/solved!
* SQL
* ETL (Extract / Transform / Load)
* Machine Learning
* Bespoke analysis
* ...
## Map-Reduce - Limitations
* MapReduce jobs independent from each others
* Network & Disk IO intensive in some cases (shuffle)
* Lack of iterative/in-memory computation
## Big Data - Beyond Map Reduce
## New frameworks - DAG
> Direct Acyclic Graph
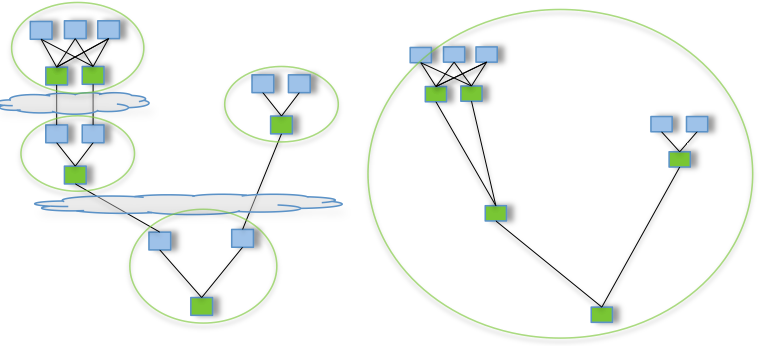
## New frameworks - DAG
* Generalization of Map-Reduce concept
* Jobs are aware of all the tasks involved
* Allows global optimization
* Better use of resources
> Spark, Tez, Drill, Dremel, Spanner, ...
## Spark
* Fundations
* Berkeley's AMPLab from 2009
* Open sourced and moved as an Apache project in 2013
* Improvements on the Map-Reduce paradigm
* In memory cluster computing
* Iterative algorithms
* Interactive & Exploratory analysis
* Batch & Streaming
Note:
* DAG system
* Java, Python, Scala,
* Popular for data science and analysis
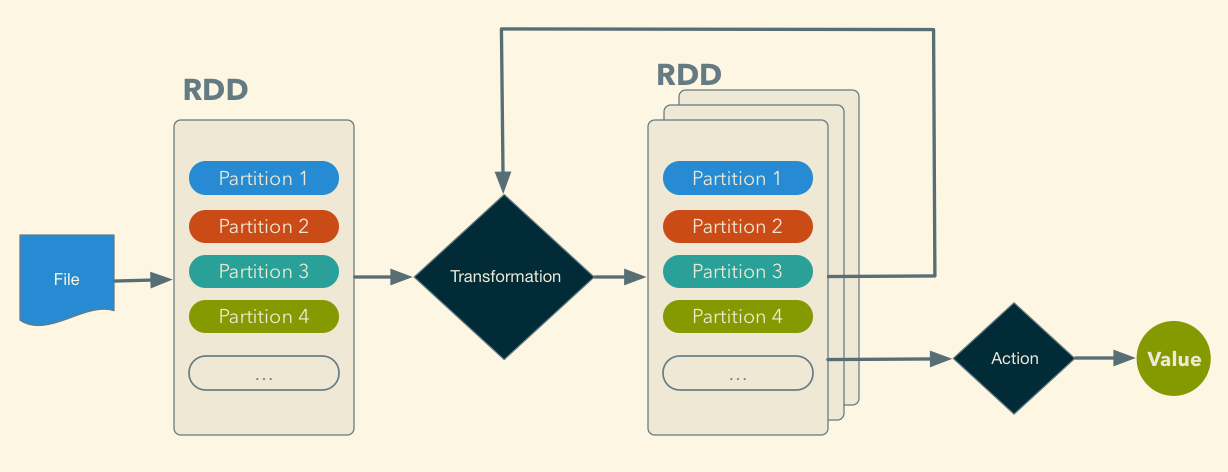
## Spark - RDD (Resilient Distributed Datasets)
> a fault-tolerant collection of elements that can be operated on in parallel
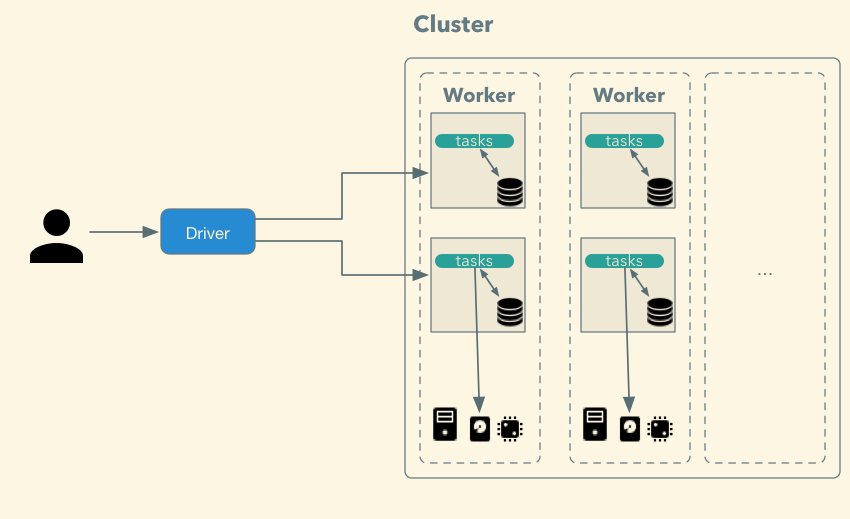
## Spark - Driver & Workers
## Spark - High Level Libraries
* SQL
* Streaming
* **Machine Learning**
* Graph
## Machine & Deep Learning
## Machine Learning
> Machine learning is a field of computer science that gives computers
the ability to learn without being explicitly programmed.
## Machine Learning
* Clustering / Classification
* Anomaly Detection
* Supervised / Unsupervised Learning
* Reinforcement Learning
* Neural Nets
## Machine Learning & Big Data
* Vast quantities of Data
* Large data sets for training
* Improvement in software/hardware
* GPU
* High Level libraries
* Broadly accessible
## Deep Learning
* Originated in the end of 50'
* Perceptron
* Frank Rosenblatt
* Neurobiology
* Neural Networks
## Perceptron
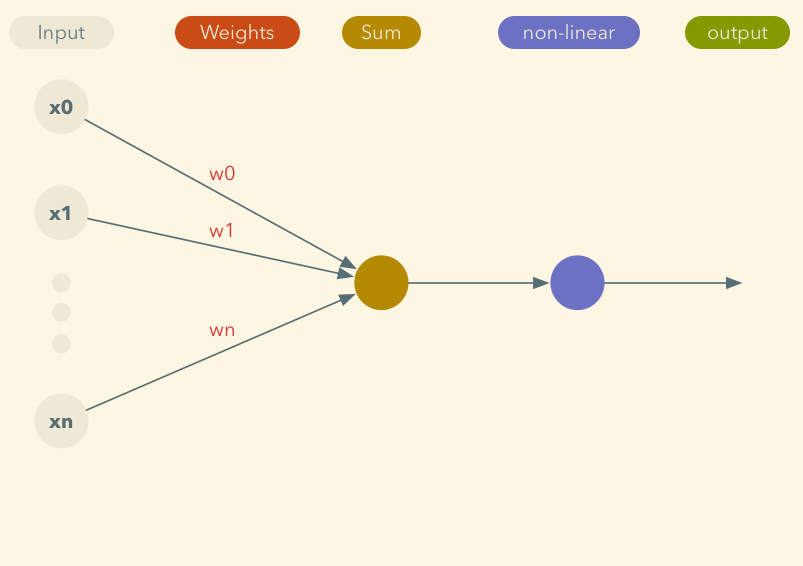
## Deep Neural Network
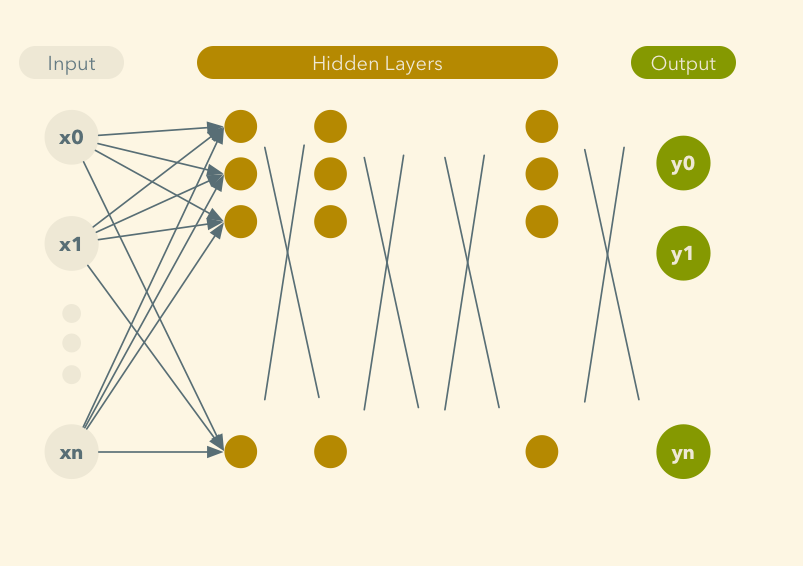
## Deep Learning
* Image classification
* Text Translation
* Speech Recognition
* Speech Synthesis
* Game
* ...
## Application to Music
* **Recommendation**
* Playlist & Marketing
* **Classification**
* Genre, Mood, Tempo, Danceability
* **Music Generation**
* Games, Ambient Music
* Techniques
* Collaborative Filtering
* Natural Language Processing
* Deep Learning